This month, we pursue our exploration of spectral properties of kernel matrices. As mentioned in a previous post, understanding how eigenvalues decay is not only fun but also key to understanding algorithmic and statistical properties of many learning methods (see, e.g., chapter 7 of my book “Learning Theory from First Principles“). This month, we look at the common situation of translation-invariant kernels in \(\mathbb{R}^d\), review asymptotic results, and provide non-asymptotic bounds which are not available in the literature in the simple form I propose (at least, I am not aware of it).
The previous episode can be summarized as follows:
- Take any independent and identically distributed data \(x_1,\dots,x_n \in \mathcal{X}\) from a probability distribution \(\mu\) and compute the \(n \times n\) kernel matrix \(K\) defined as \(K_{ij} = k(x_i,x_j)\) for a positive definite kernel \(k: \mathcal{X} \times \mathcal{X} \to \mathbb{R}\). Then, when \(n\) tends to infinity, the \(m\)-th eigenvalue of \(\frac{1}{n}K\) tends to the \(m\)-th eigenvalue of the covariance operator (from \(\mathcal{H}\) to \(\mathcal{H}\)) $$ \Sigma = \int_{\mathcal{X}} \varphi(x)\! \otimes \! \varphi(x) \, d\mu(x),$$ where \(\varphi: \mathcal{X} \to \mathcal{H}\) is a feature map representing the kernel (that is, \(k(x,y) = \langle \varphi(x),\varphi(y) \rangle\) for all \(x,y \in \mathcal{X}\)).
- While the covariance operator is a nice tool in particular in finite dimensions, when it becomes the (non-centered) covariance matrix, it is not most practical to study eigenvalues, as it is only defined implicitly through the feature map \(\varphi\). When a natural feature map can be defined (like done in a previous post for the torus \([0,\! 1]^d\) with complex exponentials), this is quite useful, but when not, this is more problematic. This is why the following integral operator is usually considered, this time from \(L_2(\mu)\) to \(L_2(\mu)\) (the space of square-integrable functions for the distribution \(\mu\) of the data), defined as $$\tag{1} Tf(x) = \int_{\mathcal{X}} k(x,y) f(y) d\mu(y).$$ It is compact and has the same non-zero eigenvalues as \(\Sigma\).
- For the torus \(\mathcal{X} = [0,\! 1]^d\) and a kernel of the form \(k(x,y) = k(x-y)\) with a translation-invariant \(1\)-periodic function \(k\), the eigenvalues are exactly the Fourier series components \( \int_{[0, 1]^d} k(x)e^{-2i \pi \omega^\top x} dx \in \mathbb{R}_+\) for \(\omega \in \mathbb{Z}^d\). While having closed-form expressions is practical for analysis, these kernels are not commonly used in practice.
Translation-invariant kernels on \(\mathbb{R}^d\)
In this post, we look at a more common and impactful situation, that is, \(\mathcal{X}= \mathbb{R}^d\), and translation-invariant kernels of the form \(k(x,y) = k(x-y)\) for \(k: \mathbb{R}^d \to \mathbb{R}\) (with a common slight overloading of notations). It is well-known that such a kernel is positive-definite if and only if its Fourier transform (assuming it exists) $$ \hat{k}(\omega) = \int_{\mathbb{R}^d} k(x) e^{-i \omega^\top x} dx$$ is non-negative, a result known as Bochner’s theorem. Here are below classical examples, with various decays of the Fourier transform, e.g., Gaussian tails, exponential tails, polynomial tails, or compact support, all with a bandwidth \(\tau\). Throughout this blog post, we privilege the normalization \(k(0)=1\) so that eigenvalues sum to one, that is, \(\sum_{m \geqslant 0} \lambda_m = 1\).
| Kernel \(k(x-y)\) | Fourier transform \(\hat{k}(\omega)\) | |
| Gaussian | \(\exp( – \frac{1}{2\tau^2} \| x\! -\! y\|_2^2 )\) | \( (2\pi \tau^2)^{d/2} \exp( – \frac{\tau^2}{2} \| \omega \|_2^2)\) |
| Abel | \(\exp( – \frac{1}{\tau} \| x – y\|_2 )\) | \(\displaystyle \frac{2^d \pi^{(d-1)/2}\Gamma( \frac{d+1 }{2})\tau^d }{(1\!+\!\tau^2 \| \omega\|_2^2)^{d/2+1/2}}\) |
| Matern | \(\exp( \frac{-\| x – y\|_2}{\tau} ) P_\alpha(\frac{\| x- y\|_2}{\tau} )\) with a polynomial \(P_{\alpha}\) | \(c_{\alpha,d} \tau^d (1\!+\!\tau^2 \| \omega\|_2^2)^{-\alpha-d/2-1/2}\) with \(\alpha \in \mathbb{N}\) |
| Student | \(\displaystyle \frac{1}{(1\!+\! \| x\!-\!y\|_2^2 / \tau^2)^{\alpha+d/2+1/2}}\) | \(\displaystyle \frac{\tau^d P_\alpha(\tau \| \omega \|_2)}{(2\pi)^d c_{\alpha,d}} \exp( – \tau \| \omega \|_2 ) \) |
| Sinc | \(\tau \frac{ \sin \frac{x-y}{\tau}}{ x- y}\) | \((\pi \tau)^d1_{[-1,1]^d} ( \tau \omega)\) |
In the table above with translation-invariant kernels and their Fourier transforms, for Matern kernels, the polynomial \(P_{\alpha}\) has degree \(\alpha\), and \(P_0(X)=1\) (we then recover the Abel kernel), \(P_1(X)=1\!+\!X\), and \(P_2(X) = 1\!+\!X\!+\!X^2/3\), and we have \(c_{d,\alpha}= 2^d \pi^{d/2}\Gamma( \alpha+\frac{d+1 }{2}) \Gamma(\alpha+\frac{1}{2})^{-1} \). See [1, page 84] for more details.
Densities. We consider a probability distribution \(\mu\) with density \(p\) with respect to the Lebesgue measure, but below, we will not necessarily need that the density sums to one to define the integral operator and its eigenvalues. As we will see below, the densities \(p\) play a similar role than Fourier transforms \(\hat{k}\) of kernels, so typical examples would be obtained from the right column of the table above, e.g., Gaussian, Student, Laplace, or uniform on a box.
Eigenvalues and their properties
We denote by \((\lambda_m(p,\hat{k}))_{m \geqslant 0}\) the eigenvalues of the integral operator \(T\), defined in Eq. \((1)\), obtained from density \(p\) and kernel \(k\) with Fourier transform \(\hat{k}\). Throughout the rest of the post, we do not assume any form of normalization, although we will often make sure that \(k(0)=1\) and \(p\) sums to one, so that eigenvalues sum to one (in general they sum to \(k(0) \int_{\mathbb{R}^d} p(x) dx\)). Because of the Fourier inversion formula \(k(x) = \frac{1}{(2\pi)^d} \! \int_{\mathbb{R}^d} \! \hat{k}(\omega) e^{ i \omega^\top x} d\omega\), we have \(k(0) = \frac{1}{ (2\pi)^d } \!\int_{\mathbb{R}^d} \! \hat{k}(\omega) d\omega\), that is, if \(k(0)=1\), then \(\hat{k}\) is pointwise non-negative and sums to \((2\pi)^d\).
The operator \(T\) has the same eigenvalues (except potentially zero) as the operator from \(L_2(\mathbb{R}^d)\) to \(L_2(\mathbb{R}^d)\), defined as: $$ Qf(x) = p(x)^{1/2} \! \! \int_{\mathbb{R}^d} \! k(x\!-\!y) f(y) p(y)^{1/2} dy.$$
As an auto-adjoint operator, there is a sequence of non-zero eigenvalues \(\lambda_m\), \(m \geqslant 0\), (the same as for \(T\)) and eigenfunctions \(\psi_m: \mathbb{R}^d \to \mathbb{R}\), which are orthonormal for \(L_2(\mathbb{R}^d)\), and such that for \(x,y \in \mathbb{R}^d\): $$\tag{2} k(x,y) = \sum_{m=0}^{+\infty} \lambda_m g_m(x) g_m(y) = \sum_{m=0}^{+\infty} \lambda_m p(x)^{-1/2} \psi_m(x) \psi_m(y) p(y)^{-1/2} .$$
We have \(\psi_m(x) = p(x)^{1/2} g_m(x)\) so that the family \((g_m)_{m \geqslant 0}\) is orthonormal for \(L_2(\mu)\) (assuming for simplicity that \(p(x)>0\)).
Basic properties. We have a few properties that will be useful for obtaining closed forms and bounds.
- Swapping: as a consequence of the interaction of convolutions and Fourier transforms (convolution theorem), \(\lambda_m(p,\hat{k}) = \lambda_m( \hat{k},{p})\) (see a proof at the end of the post). This nice symmetry should also show up in our asymptotic and non-asymptotic results on eigenvalues.
- Rescaling: for \(x \mapsto p(\alpha x)\) and \(x \mapsto k(\alpha x)\), we get the same eigenvalues multiplied by \(\alpha^{-d}\). Moreover, for \(x \mapsto \alpha^{d} p(\alpha x)\) and \(x \mapsto k(\alpha x)\), we get exactly the same eigenvalues.
- Bounds: \(p(x) \leqslant \alpha p'(x)\) for all \(x \in \mathbb{R}^d\) and \(\alpha >0\), then \(\lambda_m(p,\hat{k}) \leqslant\alpha \lambda_m(p’,\hat{k})\) for all \(m \geqslant 0\), with a similar property for scaling the kernel. This is practical to obtain non-asymptotic bounds, by bounding \(p\) or \(k\) by quantities for which we know the eigenvalues in (semi-)closed form (as we will do below for Gaussians and boxes).
A bit of history
Early papers considered one dimension, for \(p(x) = 1_{[-1,1]}(x) \) and generic kernels \(k(x,y)\) (not necessarily translation-invariant), with a clear message: the more differentiable \(k\) is, the stronger the decay of eigenvalues, with an explicit asymptotic behavior:
- Ivar Fredolhm in his original paper in 1903 had a rate in \(O(m^{-3/2})\) with one continuous derivative [5, in French].
- Hermann Weyl in 1912 gets that with one continuous derivative, we have \(\lambda_m = o(m^{-3/2})\) [7, in German], improved to \(o(n^{-2})\) in 1983 by John Reade [9]. With \(s\) derivatives, the rate \(o(n^{-s-1})\) can be obtained, still by John Reade [15].
- The explicit link with Fourier series (described in an earlier post) was made in 1931 by Einar Hille and Jacob D. Tamarkin [8].
- Closer to us (1986), there is some nice and simple non-asymptotic analysis from [2].
In this blog post, we focus on translation-invariant kernels, where multivariate extensions are quite natural, and these were originally studied by Harold Widom [3, 4] in the 1960’s. Note that there is a parallel line of work to obtain eigenvalue decays from differentiability properties of (non-necessarily translation invariant) kernels that is based on a link with Gaussian processes [16].
Summary of known results
We can classify the known results in three classes: exact, asymptotic, and non-asymptotic.
Exact expressions. For Gaussian kernels and Gaussian distributions, we obtain an explicit expression of eigenvalues and eigenvectors with a nice link with Hermite polynomials first described by [11] and presented below. The decay of eigenvalues is then exponential. For \(p\) and \(\hat{k}\) that are boxes (that is, proportional to \(1_{\| \cdot \|_\infty > c}\) for some constant \(c\)), we obtain a “semi-closed form” solution with a decay in \(m^{-m}\) in dimension one, which will be instrumental in obtaining non-asymptotic bounds (see below).
Asymptotic results. Exact equivalents can be obtained in a wide variety of situations, with two papers from Harold Widom [3, 4] which I particularly like although their proofs are quite technical and a bit difficult to follow (I may one day try to write a simplified proof).
- Unit box in one dimension [4]. For \(p(x) = \frac{1}{2\sigma} 1_{[-\sigma,\sigma]}(x)\), we have \(\lambda_m \sim \frac{1}{2\sigma} \hat{k}\big(\frac{m\pi}{2 \sigma}\big)\) for all polynomial decays (which is compatible with our later upper bound and our earlier post on periodic kernels, ouf!). For Gaussian decay, see [4, Theorem 3], where the decay is faster.
- General densities. Quite amazingly, for the general case we consider in this blog post, for polynomial decays of \(\hat{k}\) and \(p\), Widom shows in a tour de force [3] that $$\boxed{ {\rm card}\Big( \big\{ m \in \mathbb{N}, \ \lambda_m \geqslant \varepsilon \big\} \Big) \sim_{\varepsilon \to 0} \frac{1}{(2\pi)^d} {\rm vol} \Big( \big\{ (x,\omega) \in \mathbb{R}^d\! \times \! \mathbb{R}^d, p(x) \hat{k}(\omega) \geqslant \varepsilon \big\} \Big). \ \ }$$ This result is really great, as it characterizes the fine behavior of eigenvalues.
Overall, the results from Widom [3, 4] allow to get the following table, with the behavior of \(\lambda_m(p,\hat{k})\) as a function of the decay of \(p(x)\) and \(\hat{k}(\omega)\) (all constants have been removed). For examples from the table of kernels and distributions above that are not in the table below, we can simply take the closest upper-bound to obtain an upper-bound on the behavior (e.g., Gaussians are fasters that \(e^{-\| \cdot\|^{1/d}}\)).
| compact support | \(p(x) \propto e^{-\|x\|^{1/d}}\) | \(p(x) \propto \|x\|^{-\alpha}\) | |
| \(\hat{k}(\omega) \propto e^{-\|\omega\|^{1/d}}\) | \(e^{ – m^{1/d}}\) | \(e^{ – m^{1/d}}\) | \(m^{-\alpha/d}\) |
| \(\hat{k}(\omega) \propto \|\omega\|^{-\beta}\) | \(m^{-\beta/d}\) | \(m^{-\beta/d}\) | \(m^{-\alpha\beta/(d(\alpha+\beta))}\) |
Non-asymptotic results. Is it possible to get bounds with explicit constants? This post extends our earlier work [14] by providing a bound with explicit constants.
We start with the nicest situation where we know the eigenvalues in closed form (Gaussians), then move to boxes in semi-closed form, and then to non-asymptotic bounds. namely Gaussian kernels and Gaussian data.
Gaussians in closed forms
From the Mehler formula, originally proved in 1866 [6], we have, for any \(t \in [0,1)\) $$ \frac{1}{\sqrt{ \pi(1-t^2)}} \exp \Big[ \frac{ 2xyt – t^2( x^2+y^2)}{1-t^2}\Big] = \sum_{m = 0 }^\infty \frac{t^m}{ { 2^m m! \sqrt{\pi}}} H_m(x) H_m(y), \tag{3} $$ with \(H_m\) the \(m\)-th Hermite polynomial. Then \(\big( \frac{1}{ \sqrt{ 2^m m! \sqrt{\pi}}} e^{-x^2/2} H_m(x) \big)_{m \geqslant 0}\) is an orthonormal basis of \(L_2(\mathbb{R})\) (see also an earlier blog post).
Although it is not at all obvious at first, if you take \(p\) the density of the Gaussian with mean zero and variance \(\frac{1}{2} \frac{1+t}{1-t}\), that is, \(p(x) = \frac{1}{\sqrt{\pi}} \sqrt{\frac{1-t}{1+t}} \exp\big( – \frac{1-t}{1+t} x^2 \big)\), with the kernel \(k(x,y) = \exp\big( – \frac{t}{1-t^2} (x-y)^2 \big)\), and the eigenfunctions \(\psi_m(x) = \frac{1}{ \sqrt{ 2^m m! \sqrt{\pi}}} e^{-x^2/2} H_m(x)\), Eq. \((3)\) is exactly Eq. \((2)\) with eigenvalues $$ \lambda_m = t^m(1-t)$$ for \(m \geqslant 0\) (which sum to one). We can thus read out eigenvalues and eigenfunctions from the expression above. Alternatively, we could directly see that \(\psi_m\) as an eigenfunction [11, Eq. (39)].
Extension to all variances and bandwidths. Through the invariance properties, we can extend the result above to any Gaussian density with variance \(\sigma^2\), and any Gaussian kernel with bandwidth \(\tau\), that is, \(k(x,y) = \exp( – \frac{1}{2\tau^2}(x-y)^2)\), by finding the unique \(t \in [0,1)\) such that \(\frac{t}{(1-t)^2} = \rho^2 = \frac{\sigma^2}{\tau^2}\). Such \(t\) can be obtained in closed form as \(t = \frac{ 2\rho^2}{2\rho^2+1 +\sqrt{4 \rho^2 + 1}}\). When \(\rho\) tends to infinity, we have the equivalent \(t \sim 1 \, – 1/\rho\). Note that for a fixed input distribution (e.g., fixed \(\sigma\)), the exponential constant goes from zero (fast decay) for large \(\tau\) to one (slow decay) for small \(\tau\).
Extension to multiple dimensions. If we now have a Gaussian distribution with any mean and covariance matrix \(\Sigma\), with a kernel \(k(x,y) = \exp( – \frac{1}{2} (x-y)^\top T^{-1} (x-y))\), then eigenvalues are \(\prod_{j=1}^d (1-t_j) t_j^{r_j}\), for \(r \in \mathbb{N}^d\), and \(t_j \in (0,1) \) defined as \(t_j/(1-t_j)^2\) equal to the \(j\)-th eigenvalue of the matrix \(\Sigma^{1/2} T^{-1} \Sigma^{1/2} \in \mathbb{R}^d\).
When all these eigenvalues are equal, then eigenvalues are \((1-t)^d t^{\| r\|_1}\), and we obtain many multiple eigenvalues. In particular, since the number of non-negative multi-indices such that \(\|r \|_1 \leqslant s\) is equal to \({ d+s \choose s} \sim \frac{s^{d}}{d!}\), we obtain that $$ \log \lambda_m(p,\hat{k}) \sim \ – \log \frac{1}{t} \cdot ( d!)^{1/d} \cdot m^{1/d}.$$ We thus get an eigenvalue decay which is exponential, but with a slower decay when \(d\) increases.
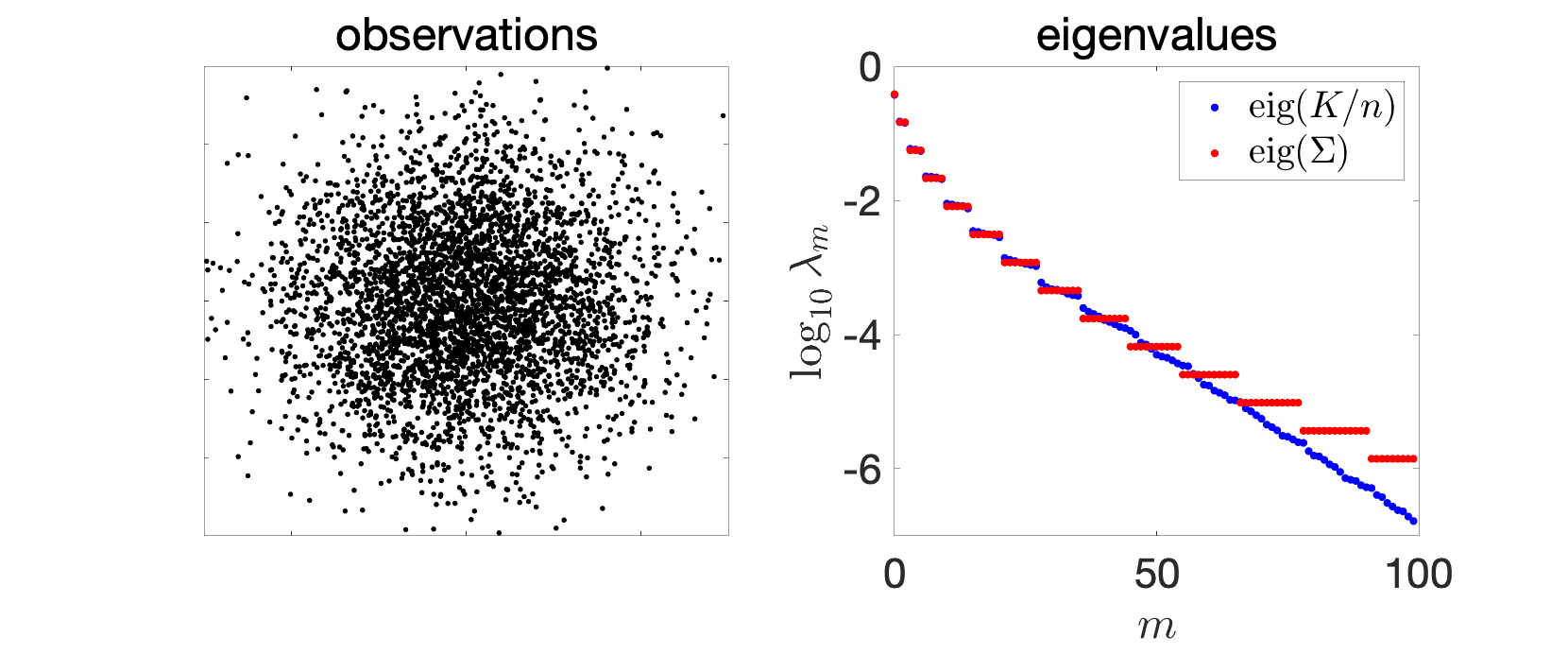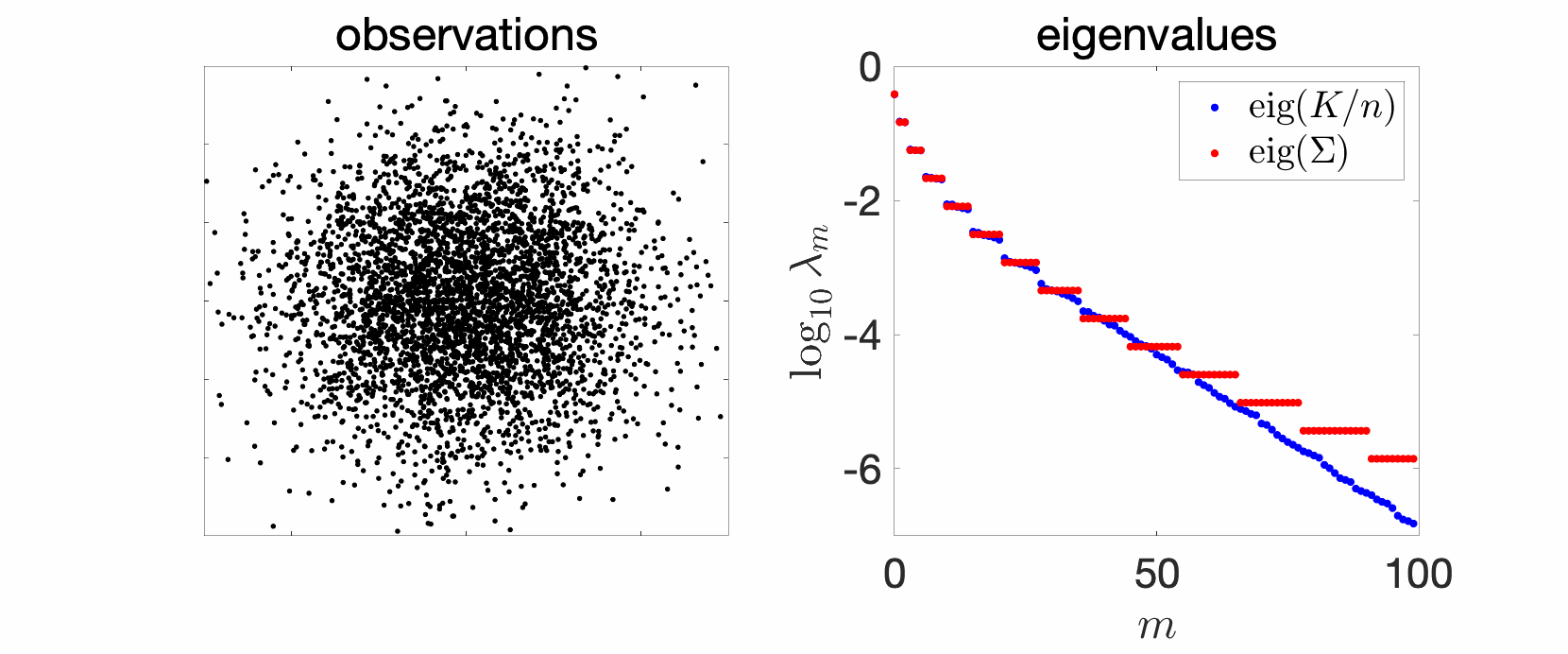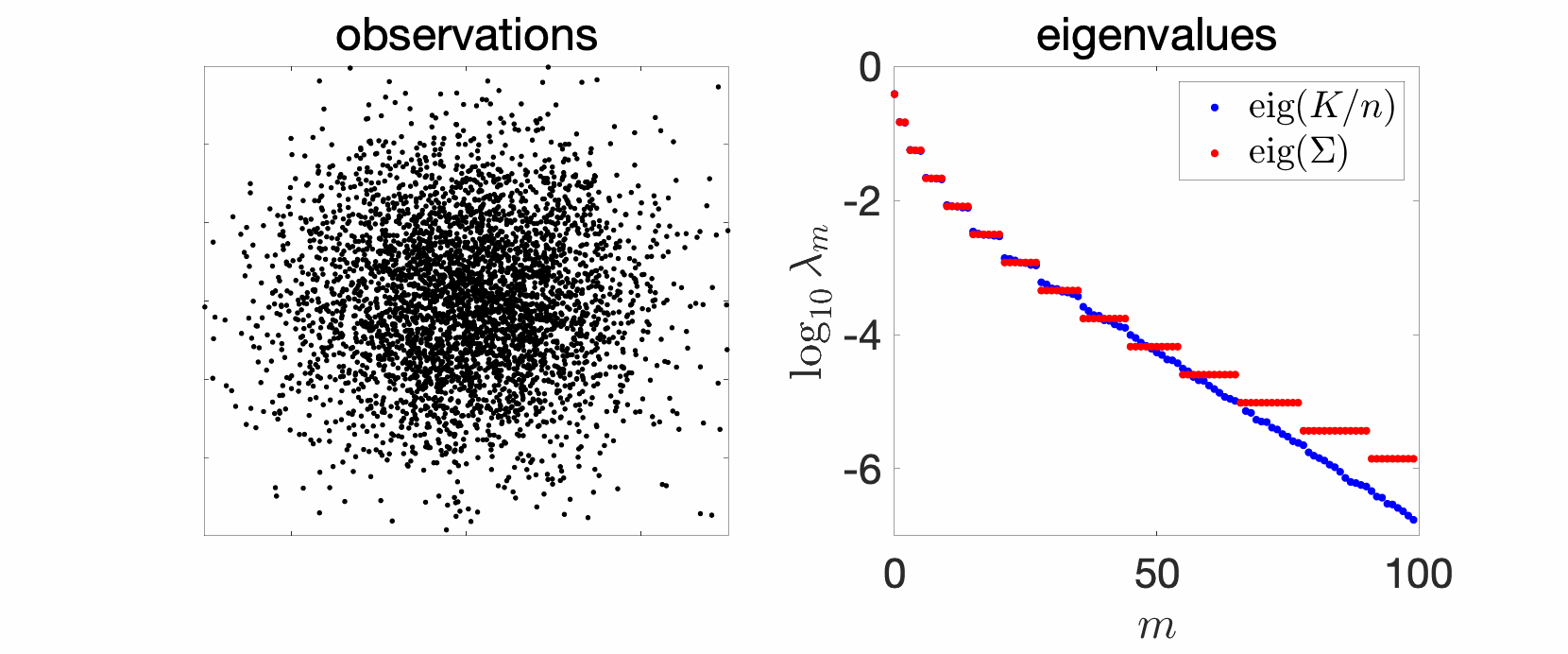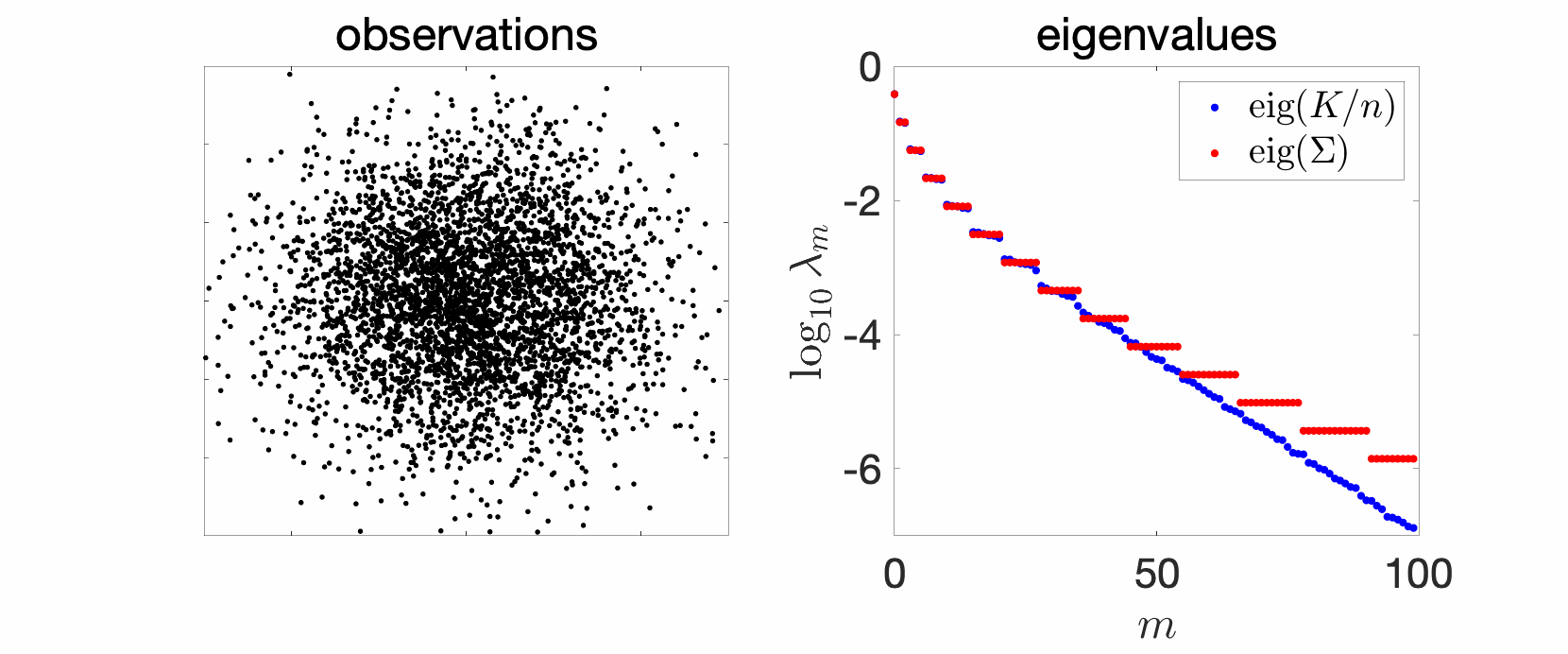
Boxes in semi-closed forms
With the box \(p(x) = \frac{1}{2\sigma}1_{[-\sigma,\sigma]}(x)\) and the kernel with Fourier transform $$\hat{k}(\omega) = \tau \pi 1_{[-1/\tau,1/\tau]}(\omega),$$ that is, $$k(x,y) = \frac{\sin (x-y)/\tau}{(x-y)/\tau},$$ then, defining $$\rho = \sigma/\tau,$$ the eigenvalues \((\lambda_m)_{m \geqslant 0}\) have a very specific behavior which has been well-studied [4, 10, 17, 18, 20, 22] in physics and signal processing.
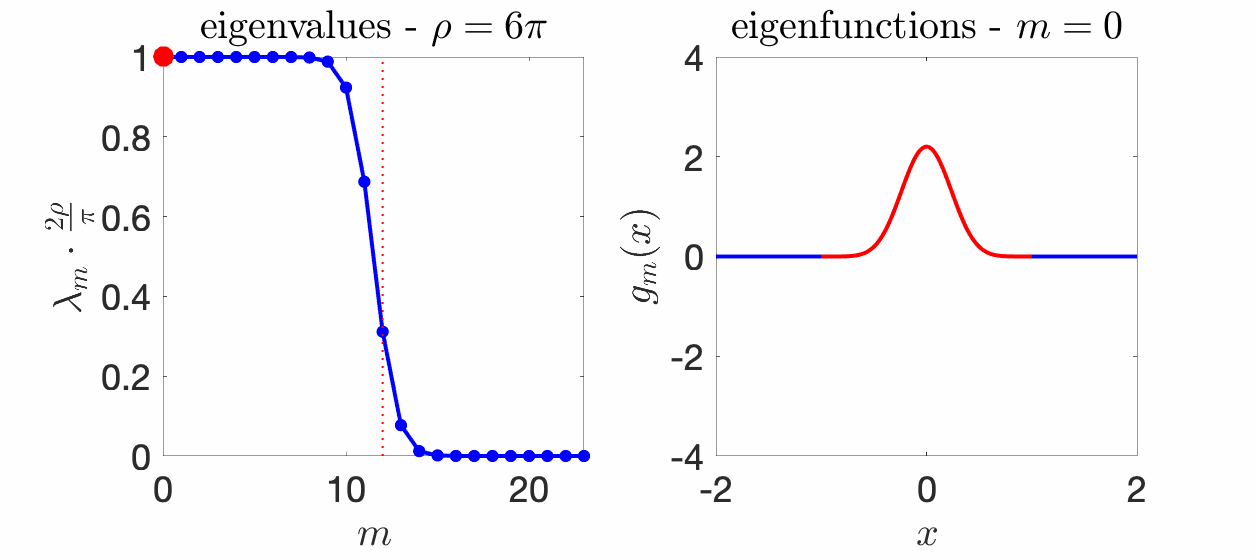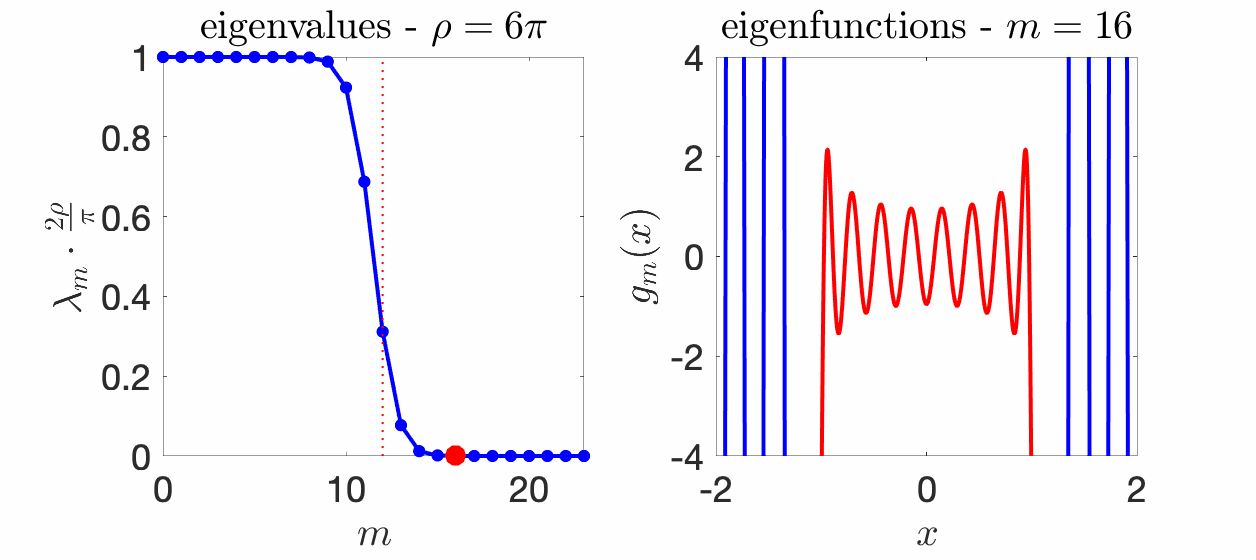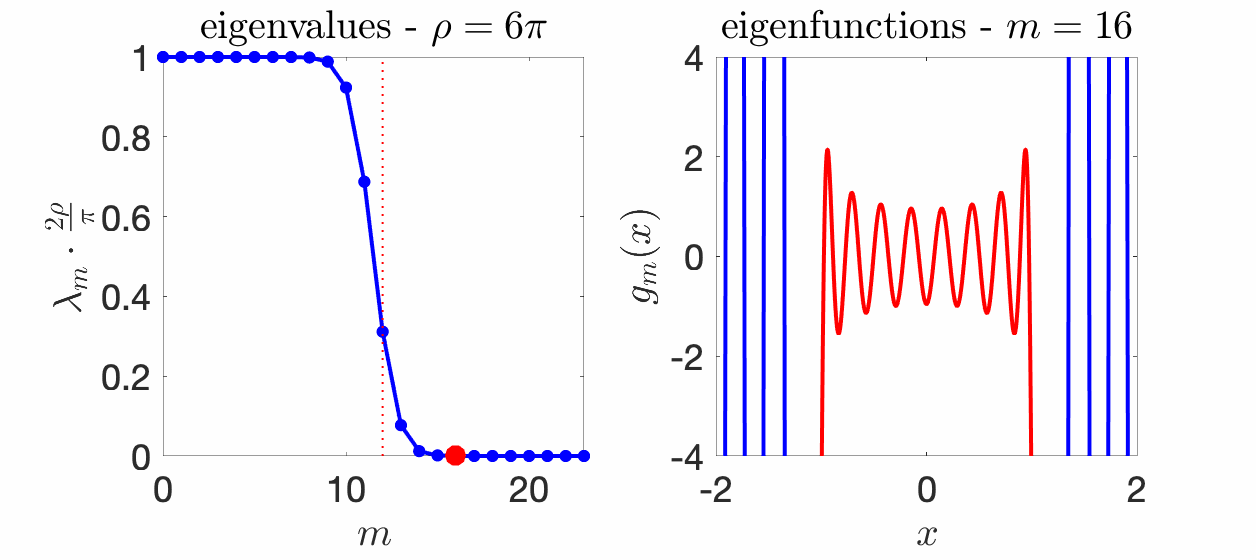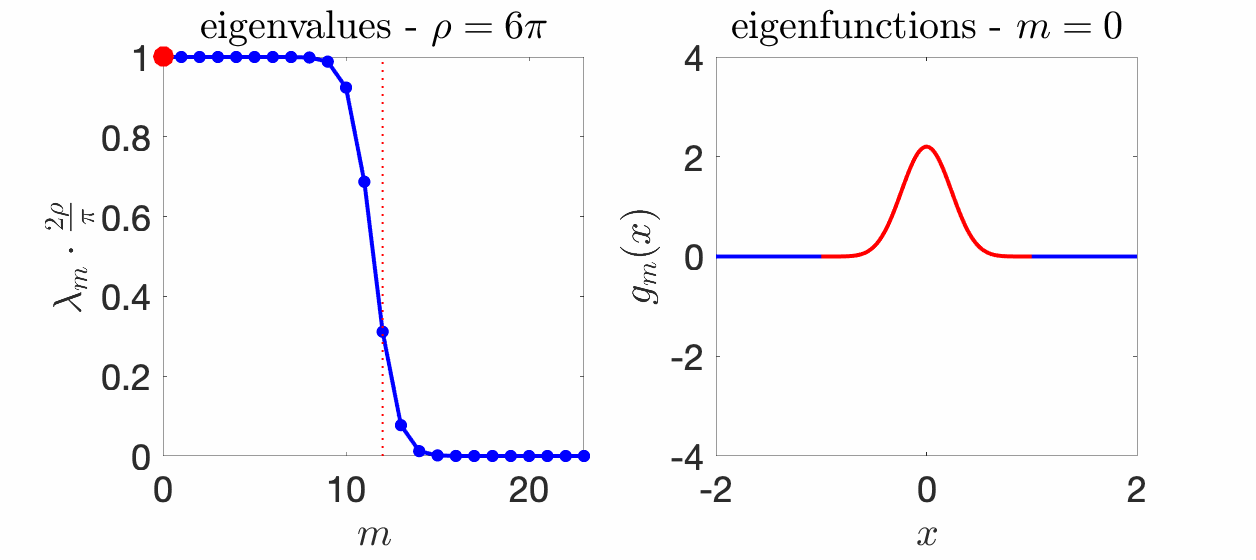
We know that the eigenvalues \((\lambda_m)_{m \geqslant 0}\) sum to one because of our choice of normalization, but we know much more. Essentially, all eigenvalues \(\lambda_m\) are less than \(\pi/(2 \rho)\), all close to \(\pi/(2 \rho)\) for \(m \ll 2 \rho / \pi\), and all close to zero if \(m \gg 2\rho \pi\). Moreover, the transition period between these two behaviors is of order \(\log \rho\). See an illustration below for several values of \(\rho\).
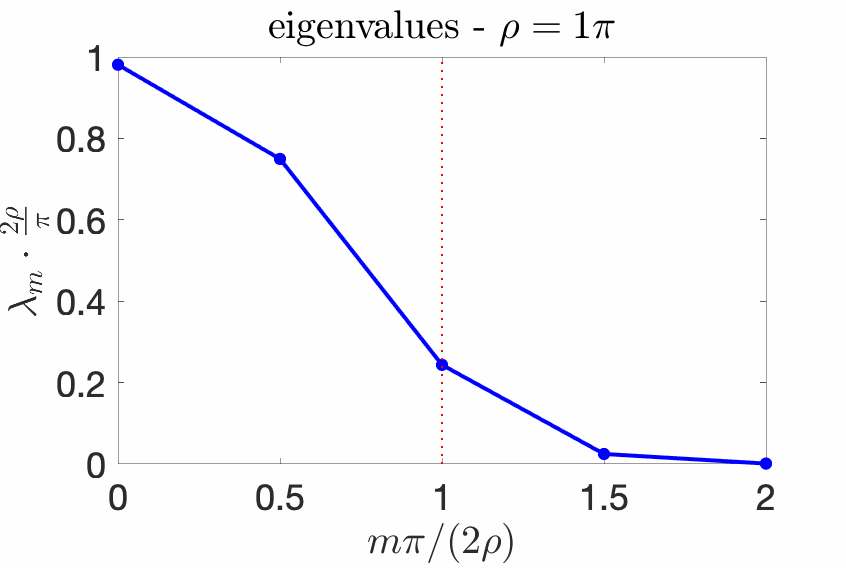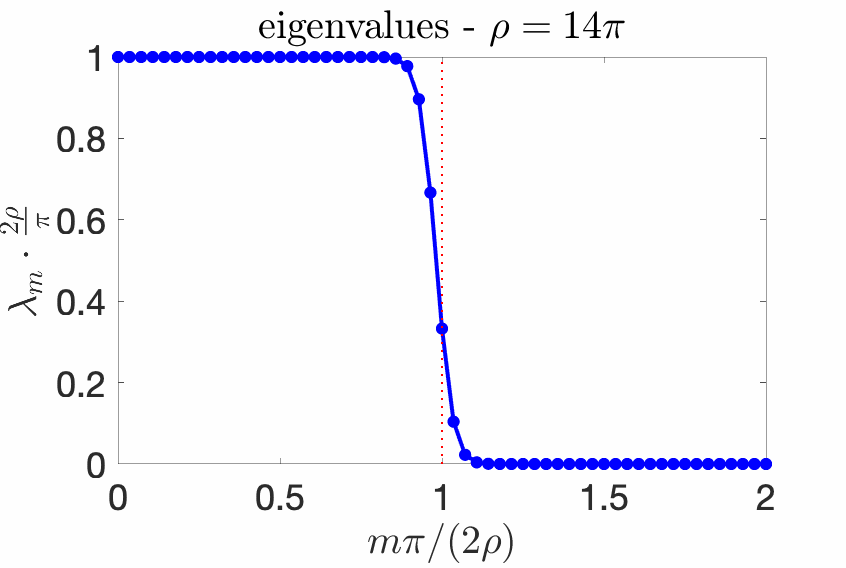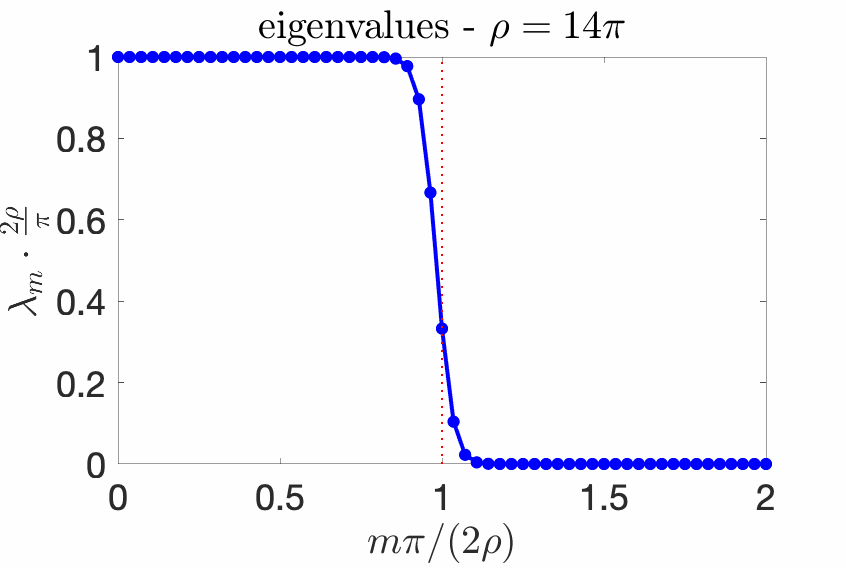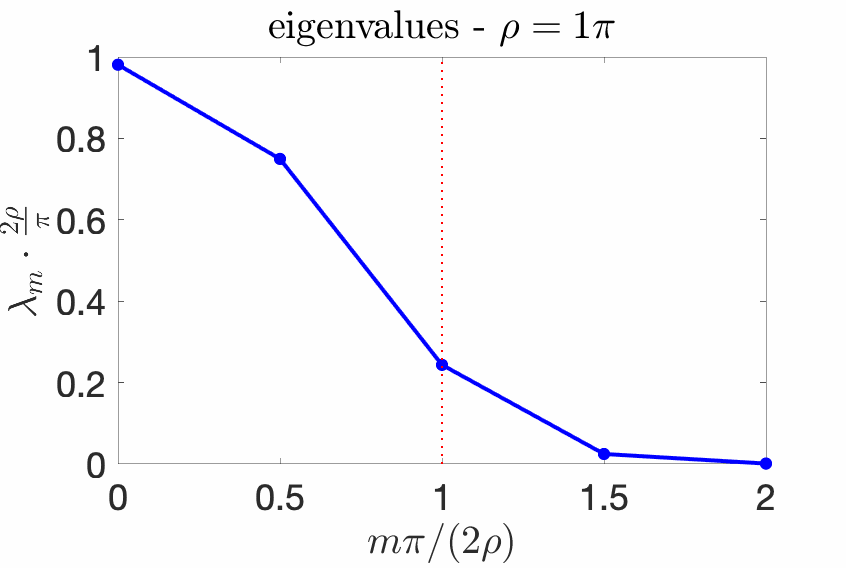
Asymptotic statements. The behavior above can be characterized with asymptotic equivalents when either \(\rho \to +\infty\) or \(m \to +\infty\):
- (super)Exponential convergence for large \(m\) (and fixed \(\rho\)): when \(m \to +\infty\), we have the equivalent \(\lambda_m \sim \frac{\pi }{2 e \rho } \Big( \frac{e \rho}{4m} \Big)^{2m+1}\) [4, p. 218].
- Exponential convergence for large \(\rho\) (and fixed \(m\)): When \(\rho \to +\infty\), \(\frac{2\rho}{\pi} \lambda_m \to 1\), with \(1 – \frac{2\rho}{\pi} \lambda_m \sim 4 \sqrt{\pi} \frac{8^m}{m!} \rho^{m+1/2} e^{-\rho}\) (Theorem 3.25 in [10]).
- Asymptotically, in the transition region, when \(\rho\) is large, for \(m \approx 2\rho/\pi+ \frac{\log \rho}{\pi^2} u\), \(\lambda_m \approx \frac{\pi}{2\rho} (1+e^u)^{-1}\) [19, Theorem 1].
Non-asymptotic statements. We have moreover statements which are true for all \(m \geqslant 0\) and \(\rho > 0\). The following bound is tight when \(m\) tends to \(+\infty\)) [12, Theorem 9]: $$ \lambda_{m} \leqslant \frac{ \pi \rho^{2m} (m!)^4}{ 4 \cdot (2m)!^2 \Gamma(m+3/2)^2}, $$ which can be further upper-bounded as $$ \lambda_{m} \leqslant \frac{\pi \rho^{2m}}{4 \Gamma(3/2)^2 } (m+1)^{-2m-1} \leqslant \frac{1}{\rho} \Big(\frac{\rho }{m+1}\Big)^{2m+1},$$ for any \(m \in \mathbb{N}\) and \(\rho > 0\). We will need later the simpler bound: $$ \tag{4} \lambda_m \leqslant 2^{\rho – 2m},$$ which can be obtained by splitting the set of \(m\)’s according to \(m+1 \geqslant \rho/2\) or \(\leqslant \rho/2\). This will allow us to derive upper-bounds for generic kernels and densities.
Eigenfunctions. The eigenfunctions associated with the integral operator and the eigenvalues \(\lambda_m\) are called “prolate spheroidal wave functions“, and appear in physics (because they satisfy a particular ordinary differential equation) and signal processing (because of its spectral properties). One nice aspect is that they define an orthonormal basis of \(L_2([-1,1])\) which can be extended to an orthogonal family in \(L_2(\mathbb{R})\), and that are band-limited functions (with support of their Fourier transform in \([-\rho, \rho]\). Moreover, these functions are they own Fourier transform (up to rescaling). For more details, see [10, 18] and the figure below for \(\rho = 6\pi\).
Multiple dimensions. We can now consider the kernel \(k\) on \(\mathbb{R}^d\) defined by products as $$\hat{k}(\omega) = (\pi \tau)^d 1_{\| \omega \|_\infty \leqslant 1/\tau},$$ and the density $$u(x) = \frac{1}{(2\sigma)^d} 1_{\| u \|_\infty \leqslant \sigma}.$$ The eigenvalues are \(\prod_{j=1}^d \lambda_{r_j}\) where \((\lambda_m)_{m \geqslant 0}\) are the eigenvalues defined above and \(r \in \mathbb{N}^d\). Given the bound in Eq. \((2)\), the eigenvalue defined by \(r \in \mathbb{N}^d\) is less than \(2^{\rho d – 2 \| r\|_1}\). The number of non-negative multi-indices such that \(\|m \|_1 \leqslant s\) is equal to \({ d+s \choose d} \leqslant \big( \frac{ e(d+s)}{d}\big)^d\) (using a classical bound, as shown in [21, Section 8.1.2]), thus, for any \(m \geqslant 0\), \(\lambda_m \leqslant 2^{\rho d – 2 s}\), where \(s\) is the largest integer such that \(\big( \frac{ e(d+s)}{d}\big)^d \leqslant m\). This leads to $$\tag{5} \lambda_m \leqslant 2^{\rho d + 2 -2 ( m^{1/d} d e^{-1} – d)} \leqslant 2^{2+2d} 2^{d( \rho – m^{1/d}/2)}.$$
Upper bounds
We use the same technique as [3, 4, 14] and use boxes to bound eigenvalues. We will use the classical inequalities for eigenvalues of sums (Weyl’s inequality): $$\lambda_m(p,\hat{k}_1+\hat{k}_2) \leqslant \lambda_m(p,\hat{k}_1) + \lambda_0(p,\hat{k}_2),$$ with a similar inequality when \(p\) is a sum of two terms.
We write \(\hat{k} = \hat{k} 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} + \hat{k} 1_{\| \cdot\|_\infty > \tau^{-1}}\), to get $$\lambda_m(p,\hat{k}) \leqslant \lambda_m(p, \hat{k} 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} ) + \lambda_0(p, \hat{k} 1_{\| \cdot\|_\infty >\tau^{-1}} ).$$ The second term can be bounded as $$\lambda_0(p, \hat{k} 1_{\| \cdot\|_\infty >\tau^{-1}} ) \leqslant \sup_{\| \omega \|_\infty > \tau^{-1}}\!\!\! | \hat{k}(\omega)| \cdot \| p \|_\infty \cdot \lambda_0(1, 1 ) = \sup_{\| \omega \|_\infty > \tau^{-1}} \!\!\! | \hat{k}(\omega)| \cdot \| p \|_\infty,$$ since for \(p = 1\) and \(\hat{k} = 1\), the operator \(Q\) is the identity. We can bound the first term as follows: $$ \begin{array}{rcl} \lambda_m(p, \hat{k} 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} ) & \leqslant & \| \hat{k} \|_\infty \lambda_m( p 1_{\| \cdot\|_\infty \leqslant \sigma} , 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} )+ \| \hat{k} \|_\infty \lambda_0( p 1_{\| \cdot\|_\infty > \sigma} , 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} ) \\ & \leqslant &\displaystyle \| \hat{k} \|_\infty \| p \|_\infty \lambda_m( 1_{\| \cdot\|_\infty \leqslant \sigma} , 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} )+ \| \hat{k} \|_\infty \sup_{\| x\|_\infty > \sigma} \! | p(x) |. \end{array}$$ Thus, overall we get $$\lambda_m(p,\hat{k}) \leqslant \| \hat{k} \|_\infty \| p \|_\infty \lambda_m( 1_{\| \cdot\|_\infty \leqslant \sigma} , 1_{\| \cdot\|_\infty \leqslant \tau^{-1}} )+ \| \hat{k} \|_\infty \!\! \sup_{\| x\|_\infty > \sigma} \! | p(x) | + \| p \|_\infty \!\!\sup_{\| \omega \|_\infty > \tau^{-1}} \!\!\! | \hat{k}(\omega)| .$$
With the choice \(\rho = \sigma / \tau = m^{1/d} / 4\), we get from Eq. \((3)\), $$\boxed{\lambda_m(p,\hat{k}) \leqslant 2 \| \hat{k} \|_\infty \| p \|_\infty \big( \frac{2}{\pi} \big)^d \cdot m 2^{- d m^{1/d}/4 } + \| \hat{k} \|_\infty \!\! \sup_{\| x\|_\infty > \sigma} \! | p(x) | + \| p \|_\infty \!\! \sup_{\| \omega \|_\infty > \tau^{-1}}\!\!\! | \hat{k}(\omega)|.\ \ \ }$$ Note that as desired, the bound is invariant by swapping \(p\) and \(\hat{k}\) (and \(\sigma\) and \(\tau^{-1}\)).
We can now take the minimum with respect to \(\sigma\) and \(\tau\) such that \(\rho = \sigma / \tau = m^{1/d} / 4\), to obtain a series of explicit upper bounds, which recovers in several cases the asymptotic bounds from Harold Widom [3].
Compact support. If \(p\) has compact support included in the \(\ell_\infty\)-ball of radius \(\sigma\), we get $$\lambda_m(p,\hat{k}) \leqslant 2 \| \hat{k} \|_\infty \| p \|_\infty \big( \frac{2}{\pi}\big)^d \cdot m 2^{- d m^{1/d}/4 } + \| p \|_\infty \!\! \sup_{\| \omega \|_\infty > \sigma^{-1} m^{1/d} / 4 }\!\!\! | \hat{k}(\omega)| .$$ Thus, for kernels with polynomial decay (such as Matern / Sobolev kernels of order \(\beta/2 > d/2\)), that is, \(\hat{k}(\omega) = O( \|\omega\|_\infty^{-\beta})\), we get \(\lambda_m = O(m^{-\beta/d})\), which is traditional upper-bound (with explicit constants if needed from the identity above), and in fact the asymptotic order obtained in [3].
For the Gaussian kernel (and still compact support), the first term dominates and we get \(\lambda_m = O(\exp(-c m^{1/d})\) for some constant \(c\) that can be made explicit, which is slower than the asymptotic order obtained in [4].
Beyond compact support. For example, if \(p(x)\) has tails in \(\| x\|^{-\alpha}\) and \(\hat{k}(\omega)\) has tails in \(\| \omega\|^{-\beta}\), with \(\alpha, \beta > d,\) then, with \(\tau \propto m^{-\frac{\alpha }{d(\alpha+\beta)}}\), we get \(\lambda_m = O \big( m^{-\frac{\alpha \beta}{d(\alpha+\beta)}} \big)\). In other words, heavier tails of \(p(x)\) will reduce the decay of the spectrum.
Conclusion
In this blog post, I tried to derive in the simplest possible way bounds on the decay of eigenvalues for translation-invariant kernels for as generic as possible densities. These results are commonly used in learning theory and statistics [21, 24, 25, 26, 28], but an explicit and simple bound is hard to find. The analysis is based on explicit expansions for box kernels and densities. These bounds provide a non-asymptotic control that is complementary to the asymptotic results from Harold Widom [3, 4].
Other types of kernels could be considered, such as product kernels on the sphere of the form \(k(x,y) = k(x^\top y)\), with potential links with other spherical harmonics [27]. Eigenvalue decays also have relationships with leverage scores [23], a topic for another post.
References
[1] Carl E. Rasmussen, Christopher K. I. Williams. Gaussian Processes for Machine Learning. MIT Press, 2006.
[2] Chung-Wei Ha. Eigenvalues of differentiable positive definite kernels. SIAM Journal on Mathematical Analysis 17.(2):415-419, 1986.
[3] Harold Widom. Asymptotic behavior of the eigenvalues of certain integral equations. Transactions of the American Mathematical Society, 109(2), 278-295, 1963.
[4] Harold Widom. Asymptotic behavior of the eigenvalues of certain integral equations. II. Archive for Rational Mechanics and Analysis, 17(3), 215-229, 1964.
[5] Ivar Fredholm. Sur une classe d’équations fonctionnelles. Acta Mathematica, 27(1):365-390, 1903.
[6] Mehler, Ferdinand Gustav. Ueber die Entwicklung einer Function von beliebig vielen Variabeln nach Laplaceschen Functionen höherer Ordnung“, Journal für die Reine und Angewandte Mathematik, (66):161–176, 1866.
[7] Hermann Weyl. Das asymptotische verteilungsgesetz der eigenwerte linearer partieller differentialgleichungen (mit einer anwendung auf die theorie der hohlraumstrahlung). Mathematische Annalen, 71: 441-479, 1912
[8] Einar Hille, Jacob D. Tamarkin. On the characteristic values of linear integral equations. Acta Mathematica, 57(1):1-76, 1931.
[9] John B. Reade. Eigenvalues of positive definite kernels. SIAM Journal on Mathematical Analysis 14(1):152-157, 1983.
[10] Andrei Osipov, Vladimir Rokhlin, Hong Xiao. Prolate Spheroidal Wave Functions of Order Zero. Series in Applied Mathematical Sciences, Springer, 2013.
[11] Huaiyu Zhu, Christopher K. I. Williams, Richard Rohwer, and Michal Morciniec. Gaussian regression and optimal finite-dimensional linear models. In Neural Networks and Machine Learning. Springer-Verlag, 1998
[12] Vladimir Rokhlin and Hong Xiao. Approximate formulae for certain prolate spheroidal wave functions valid for large values of both order and band-limit. Applied and Computational Harmonic Analysis, 22(1), 105-123, 2007.
[13] Li-Lian Wang. Analysis of spectral approximations using prolate spheroidal wave functions. Mathematics of computation, 79(270), 807-827, 2010.
[14] Zaid Harchaoui, Francis Bach, and Eric Moulines. Testing for Homogeneity with Kernel Fisher Discriminant Analysis, Advances in Neural Information Processing Systems, 2007. Long version (HAL technical report 00270806).
[15] John B. Reade. Positive definite \(C^p\) kernels. SIAM Journal on Mathematical Analysis, 17(2), 420-421, 1986.
[16] Klaus Ritter, Grzegorz W. Wasilkowski, and Henryk Woźniakowski. Multivariate integration and approximation for random fields satisfying Sacks-Ylvisaker conditions. The Annals of Applied Probability (1995): 518-540, 1995.
[17] David Slepian. Some asymptotic expansions for prolate spheroidal wave functions. Journal of Mathematics and Physics, 44(1-4):99-140, 1965.
[18] Li-Lian Wang. A review of prolate spheroidal wave functions from the perspective of spectral methods. Journal of Mathematical Study, 50(2):101-143, 2017.
[19] Henry J. Landau, Harold Widom. Eigenvalue distribution of time and frequency limiting. Journal of Mathematical Analysis and Applications, 77(2): 469-481, 1980.
[20] Henry J. Landau. On the density of phase-space expansions. IEEE Transactions on Information Theory, 39(4):1152-1156, 1993.
[21] Francis Bach. Learning Theory from First Principles. MIT Press, 2024.
[22] Aline Bonami, Abderrazek Karoui. Uniform bounds of prolate spheroidal wave functions and eigenvalues decay. Comptes Rendus. Mathématique 352(3):229-234, 2014.
[23] Edouard Pauwels, Francis Bach, and Jean-Philippe Vert. Relating leverage scores and density using regularized Christoffel functions. Advances in Neural Information Processing Systems, 2018.
[24] Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm. Foundations of Computational Mathematics 7: 331-368, 2007.
[25] Shahar Mendelson and Joseph Neeman. Regularization in kernel learning. The Annals of Statistics, 38(1), 526-565, 2010.
[26] Francis Bach. On the Equivalence between Kernel Quadrature Rules and Random Feature Expansions. Journal of Machine Learning Research, 18(19):1-38, 2017.
[27] Alex Smola, Zoltán Ovári, and Robert C. Williamson. Regularization with dot-product kernels. Advances in Neural Information Processing Systems, 2000.
[28] Loucas Pillaud-Vivien, Alessandro Rudi, Francis Bach. Statistical Optimality of Stochastic Gradient Descent on Hard Learning Problems through Multiple Passes. Advances in Neural Information Processing Systems (NIPS), 2018.
Proof of \(\lambda_m(p,\hat{k}) = \lambda_m( \hat{k},{p})\)
We introduce the Fourier transform operator \(F\) defined as \(Ff(\omega) = \int_{\mathbb{R}^d} f(x) e^{- i \omega^\top x} dx\), the inverse Fourier operator is \(\frac{1}{(2\pi)^d} F^\ast\), where \(F^\ast\) is the adjoint of \(F\), such that \(F^\ast F = (2\pi)^d I\). We also denote \(M(r)\) the pointwise multiplication operator by the function \(r\) (defined by \([M(r)f](x) = r(x) f(x)\)). Using the fact that the Fourier transform of a convolution is the product of Fourier transforms, we can write \(Q\) as $$ Q = \frac{1}{(2\pi)^d} M(p)^{1/2} F^\ast M(\hat{k}) F M(p)^{1/2} = \frac{1}{(2\pi)^d} M(p)^{1/2} F^\ast M(\hat{k})^{1/2} M(\hat{k})^{1/2} F M(p)^{1/2}.$$ This implies that the eigenvalues of \(Q\) are the same as the one of $$ \frac{1}{(2\pi)^d} M(\hat{k})^{1/2} F M(p)^{1/2} M(p)^{1/2} F^\ast M(\hat{k})^{1/2} = \frac{1}{(2\pi)^d} M(\hat{k})^{1/2} F M(p) F^\ast M(\hat{k})^{1/2}. $$ Thus, the roles \(p\) and \(\hat{k}\) play interchangeable roles, that is, $$ \lambda_m(p,\hat{k}) = \lambda_m( \hat{k},{p}).$$
Great to see part two is out! I’d been looking forward to these results—really useful post and hard to find anywhere else
I have been interested in identifying the spectra of kernel integral operators recently, so this was a fun and helpful read.
Recently, I noticed a cute fact while deriving the eigenvalues of the multidimensional Gaussian input + Gaussian kernel problem setup: when T=\Sigma (in your “Extension to multiple dimensions” section), the eigenvalues are the powers of (the inverse of) the golden ratio. Also, there are surprisingly simple closed-form expressions for the n-th moment (the sum of nth powers) of the eigenvalues.
Perhaps for many kernels, it might be easier to derive (or approximate) the eigenvalue moments instead of the individual eigenvalues. However, I wonder how difficult it would be to compute the bounds on the individual eigenvalues from the analytical expression of the eigenvalue moments…
Goog suggestion. Going from moments to eigenvalue decays is feasible. I don’t know how to get the moments efficiently from just k and p.
Francis