Quantities of the form \(\displaystyle \log \Big( \sum_{i=1}^n \exp( x_i) \Big)\) for \(x \in \mathbb{R}^n\), often referred to as “log-sum-exp” functions are ubiquitous in machine learning, as they appear in normalizing constants of exponential families, and thus in many supervised learning formulations such as softmax regression, but also more generally in (Bayesian or frequentist) probabilistic modelling. Moreover, as often used in optimization, they are a standard way of performing a soft maximum. In this context, the function defined as $$ \displaystyle f_\varepsilon(x) = \varepsilon \log \Big( \sum_{i=1}^n \exp( x_i / \varepsilon) \Big),$$ is such that \( \displaystyle \lim_{\varepsilon \to 0^+} f_\varepsilon(x) = \max\{x_1,\dots,x_n\}\).
Is it possible to go from the maximum back to the softmax \(f_\varepsilon(x)\) (for any strictly positive \(\varepsilon\), and thus equivalently for \(\varepsilon=1\)) ? Beyond being a nice mathematical puzzle, this would be useful for very large \(n\) when the maximization problem could be easier than the summation problem (more on this below).
While this seems at first impossible, the Gumbel trick provides a surprising randomized solution. We consider adding some independent and identically distributed random variables \(\gamma_1,\dots,\gamma_n\), to form the vector \(x + \gamma \in \mathbb{R}^n\) and takes its maximum component, that is, $$
y = x + \gamma \mbox{ and } z = \max \big\{ y_1,\dots, y_n \big\} = \max \big\{ x_1 + \gamma_1,\dots,x_n +\gamma_n \big\}.$$ With a well chosen distribution for the components of \(\gamma\), we exactly have $$\mathbb{E} z =
\mathbb{E} \max \big\{ y_1,\dots, y_n \big\} = \mathbb{E} \max \big\{ x_1 + \gamma_1,\dots,x_n +\gamma_n \big\} = \log \Big( \sum_{i=1}^n \exp( x_i) \Big).$$ This is achieved by the Gumbel distribution, hence the name “Gumbel trick” (the first applications within machine learning seem to be from [1] and [2], while this is a well-known fact in social sciences, see, e.g., [3]). We first make a detour through exponential distributions.
Minimum of independent exponential distributions
A random variable \(T\) is distributed according to the exponential distribution with parameter \(\lambda \in \mathbb{R}\), if it is supported on the positive real line and its density there is equal to \(t \mapsto \lambda \exp( – \lambda t).\) We have these classical properties:
- \(\mathbb{E} T = 1/\lambda\) and \({\rm var}(T) = 1/ \lambda^2\).
- \(T\) has the same distribution as \(-( 1/\lambda)\log U\), where \(U\) has a uniform distribution on \([0,1]\), leading to a simple algorithm to sample \(T\).
A key property which is used heavily in point processes and queuing theory is characterizing the minimum and minimizer of independent exponentially distributed random variables.
Proposition. Given \(n\) independent variables \(T_i\) distributed according to exponential distributions with parameter \(\lambda_i\), \(i=1,\dots,n\), the minimum \(V = \min \{T_1,\dots,T_n\}\) is distributed according to an exponential distribution with parameter \(\lambda_1+\dots+\lambda_n\), and the minimizer \(i^\ast= \arg \min_{i \in \{1,\dots,n\}} T_i\) (breaking ties arbitrarily) is distributed according to a multinomial distribution of parameter \(\pi\) with \(\displaystyle \pi_i = \frac{\lambda_i}{ \lambda_1 + \cdots + \lambda_n}\), for \(i \in \{1,\dots,n\}\). Moreover, \(i^\ast\) and \(V\) are independent.
(simple) Proof. A direct integration shows that $$ \mathbb{P}( T \geq u) = \int_{u}^{+\infty} \lambda \exp( -\lambda t) = \exp(-\lambda u).$$ We can then directly compute the probability, for a fixed \(i \in {1,\dots,n}\) and \(u \in \mathbb{R}_+\): $$
\mathbb{P}( I^\ast = i, V \geq u) = \mathbb{P}( T_i \geq u, \forall j \neq i, T_j \geq T_i),$$ which is equal by independence of all \(T_j\)’s to $$ \int_{u}^{+\infty} \Big( \prod_{ j\neq i} \exp( – \lambda_j t_i) \Big) \lambda_i \exp( – \lambda_i t_i) dt_i = \exp\Big( – u \sum_{i=1}^n \lambda_i \Big) \times \frac{\lambda_i}{ \lambda_1 + \cdots + \lambda_n},$$ which exactly shows the desired result (both independence and the claimed distributions).
From exponential to Gumbel distributions
A real random variable \(\Gamma\) is distributed according to a Gumbel distribution with parameter \(x \in \mathbb{R}\), if it is equal in distribution to \(\Gamma = -\log T – C\), where \(T\) is distributed according to an exponential distribution of parameter \(\lambda = \exp(x)\), and \(C\approx 0.5772\) is the Euler constant (note that in some conventions, \(C\) is not subtracted). We have the following properties:
- \(\mathbb{E} \Gamma = x\) where Indeed, we have: $$ \mathbb{E} \Gamma= -\int_0^{+\infty} \log (y\exp(-x)) \exp(-y) dy\ – C= x \ – \int_0^{+\infty} (\log y)\exp(-y) dy \ – C = x,$$ with a standard property of the Euler constant.
- \({\rm var}(\Gamma) = \frac{\pi^2}{6}\) (proof left as an exercise, derivatives of the Gamma function could be handy).
- \(\Gamma\) has the same distribution as \(x – C – \log( – \log U) \), where \(U\) has a uniform distribution on \([0,1]\), leading to a simple algorithm to sample \(\Gamma\).
- The density of \(\Gamma\) is \(p(\gamma) = \exp( x-\gamma -C – \exp( x – \gamma – C) )\), as shown below for \(x=0\).
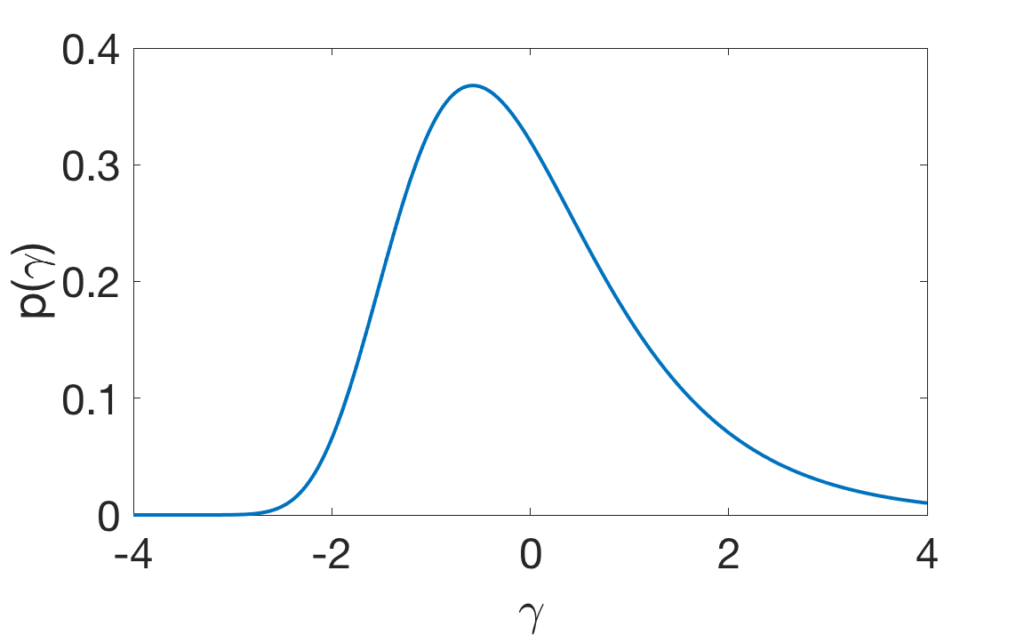
The proposition above on exponential distributions leads to the following result.
Proposition. Given \(n\) independent variables \(\Gamma_i\) distributed according to Gumbel distributions with parameter \(x_i\), \(i=1,\dots,n\), the maximum \(Z = \max \{\Gamma_1,\dots,\Gamma_n\}\) is distributed according to a Gumbel distribution with parameter (and thus mean) \(\log \big( \sum_{k=1}^n \exp(x_k) \big)\), the minimizer \(i^\ast= \arg \max_{i \in {1,\dots,n}} \Gamma_i\) (breaking ties arbitrarily) is distributed according to a multinomial distribution of parameter \(\pi\) with \(\displaystyle \pi_i = \frac{\exp(x_i)}{ \exp(x_1) + \cdots + \exp(x_n)}\), for \(i \in {1,\dots,n}\). Moreover, \(i^\ast\) and \(Z\) are independent.
Applications in machine learning
The Gumbel trick can be used in mainly two ways: (a) the main goal is to approximate the expectation using a finite average or using stochastic gradients (then only the value of the maximum is used), (b) the minimizer is used for sampling purposes. I will focus only on the first type of applications and refer to the very nice posts of Tim Vieira, Chris Maddison, and Laurent Dinh for the sampling aspects.
Log-partition functions
We consider \(d\) finite sets \(\mathcal{X}_1,\dots,\mathcal{X}_d\), and a probability mass function at \(x = (x_1,\dots,x_d)\) of the form: $$p(x) = p(x_1,\dots,x_d) = \exp( f(x)\ – A(f)),$$ where \(f: \mathcal{X}_1 \times \dots \times \mathcal{X}_d \to \mathbb{R}\) is a any function, and $$ A(f) = \log \big( \sum_{x_1 \in \mathcal{X}_1,\dots,x_d \in \mathcal{X}_d} \exp( f(x) ) \big)$$ is the so-called log-partition function (which is here to make the probability mass sum to one). The cardinality of \(\mathcal{X}_1 \times \dots \times \mathcal{X}_d\) is exponential in \(d\) and thus the sum defining \(A(f)\) cannot in general be computed even for moderate \(d\). Since computing \(A(f)\) or its derivatives is a key step in many inference tasks, finding approximations is one of the standard computational problems in probabilistic modelling.
The Gumbel trick allows to go from maximization problems to “log-sum-exp” problems, and is only useful when the maximization problem is easy to solve while the “log-sum-exp” problem is not. Can this really happen? In other words…
Is the Gumbel trick useful?
There are many conditions under which combinatorial optimization problems can be solved in polynomial time, but two properties have emerged as crucial (at least in machine learning applications): (1) dynamic programming, and (2) linear programming. For simplicity, I will illustrate them for binary problems where \(\mathcal{X}_i = \{0,1\}\) for all \(i\), and so-called “cut functions” \(f(x) = \sum_{i,j = 1}^d w_{i,j} x_i x_j + \sum_{i=1}^d w_i x_i\), for arbitrary scalar weights \(w_{i,j}\), \(w_i\).
- Dynamic programming: this corresponds to the situations where most of the weights \(w_{i,j}\) are equal to zero, with the graph on the vertex set \(\{1,\dots,n\}\) with edge set equal to the pairs \((i,j)\) with \(w_{i,j}\neq 0\), being a tree, or a chain.
For example, consider \(f(x) = \sum_{i=1}^{d-1} w_{i,i+1} x_i x_{i+1} + \sum_{i=1}^d w_i x_i\). In this situation, one can compute sequentially the functions (with increasing index \(k\)) $$ f_k(x_k) = \max_{x_1,\dots,x_{k-1}} \sum_{i=1}^{k-1} w_{i,i+1} x_i x_{i+1} + \sum_{i=1}^k w_i x_i,$$ noticing that $$f_{k+1}(x_{k+1}) = \max_{x_{k} \in \{0,1\}} f_k(x_k) + w_{k-1,k} x_k x_{k+1} + w_{k+1} x_{k+1}, $$ which can be computed easily; the recursion leads to the desired value \(\max_{x_{d} \in \{0,1\}} f_d(x_d)\).
In order to obtain the identity above, we have simply used the property $$\max\{ A + B, C + B\} = B + \max \{A,C\}.$$ However, this property is also true for the softmax, as $$\log \big( \exp(A + B) + \exp(C + B) \big) = B+ \log \big( \exp(A) + \exp(C ) \big).$$ Thus, the same dynamic programming strategy works for softmax, and using the Gumbel trick is here useless. (here, we have described a particular instance of the sum-product and max-product algorithms for graphical models).
- Linear programming: for the particular generic quadratic binary problem, we can write for any \(x_i,x_j \in \{0,1\}\), \(x_i x_j = \min \{x_i,x_j\}\), and, if all \(w_{i,j}\) are non-positive (and here no constraint regarding having many zero values), then the function \(g: \mathbb{R}^d \to \mathbb{R}\) defined as \(g(x) = \sum_{i,j = 1}^d w_{i,j} \min \{x_i,x_j\} + \sum_{i=1}^d w_i x_i\) is concave and equal to \(f\) for \(x \in \{0,1\}^d\). The convex relaxation of computing \(\max_{x \in \{0,1\}^d} f(x)\) is \(\max_{x \in [0,1]^d} f(x)\), which is a concave maximization problem, which can be solved in polynomial time (it can be cast as a linear programming problem). For this particular problems, due to a property called submodularity, the convex relaxation happens to be tight. In these situations, maximizing is feasible while “log-sum-exp” is not. However, the Gumbel trick requires to perturb \(f(x)\) with a different random values for all \(2^d\) assignments of \((x_1,\dots,x_d)\), thus totally losing the structure above. Therefore, using the Gumbel trick is here also useless.
Thus it seems that for classical situations where maximization can be done in polynomial time, the Gumbel trick is useless, either because performing log-sum-exp is as simple (for dynamic programming), or because maximization is intractable once the Gumbel perturbations are added (for linear programming). Can we make it useful?
Separable Gumbel perturbations
This is where Tamir Hazan and Tommi Jaakkola [4] come in with the following very nice and important result, which is true beyond cut functions, and shows that with a separable random perturbation, we get an upper-bound of the log-partition function.
Proposition. Given \(d\) random functions \(\gamma_i : \mathcal{X}_i \mapsto \mathbb{R}\), \(i=1,\dots,d\), such that each value (within and across the functions) is sampled independently distributed from a Gumbel distribution with zero mean, then $$A(f) \leq \mathbb{E} \Big[ \max_{x_1 \in \mathcal{X}_1,\dots,x_d \in \mathcal{X}_d} f(x) + \sum_{i=1}^d \gamma_i(x_i)\Big].$$
Proof. We can show the result by induction on \(d\), by first conditioning on \(\gamma_d\) to get $$\mathbb{E} \Big[ \! \max_{x_1,\dots,x_d} \!f(x_1,\dots,x_d) + \! \sum_{i=1}^d \gamma_i(x_i)\Big] = \mathbb{E} \bigg[\mathbb{E} \Big[ \! \max_{x_1,\dots,x_d} \!f(x_1,\dots,x_d) + \! \sum_{i=1}^d \gamma_i(x_i) \ \Big| \ \gamma_d \Big] \bigg], $$ and the property that the expectation of the max is larger than the max of the expectation to get the lower-bound $$ \mathbb{E} \bigg[ \max_{x_d} \mathbb{E} \Big[ \! \max_{x_1,\dots,x_{d-1}} \!f(x_1,\dots,x_d) + \! \sum_{i=1}^d \gamma_i(x_i) \ \Big| \ \gamma_d \Big] \bigg].$$ It is equal to $$ \mathbb{E} \bigg[ \max_{x_d} \Big\{ \gamma_{d}(x_d) + \mathbb{E} \Big[ \! \max_{x_1,\dots,x_{d-1}} \!f(x_1,\dots,x_d) + \! \sum_{i=1}^{d-1} \gamma_i(x_i) \ \Big| \ \gamma_d \Big] \Big\} \bigg], $$ which is lower-bounded by applying the result for \(d-1\), by $$ \mathbb{E} \max_{x_d} \Big\{ \gamma_d(x_d) + \log \Big( \sum_{x_1 ,\dots,x_{d-1}} \exp(f(x))\Big) \Big\} = \log \Big( \sum_{x_1 ,\dots,x_{d}} \exp(f(x))\Big),$$ by applying the regular Gumbel trick to \(\gamma_d\).
For binary problems like for cut-functions, this corresponds to adding to \(f(x) = \sum_{i,j = 1}^d w_{i,j} x_i x_j + \sum_{i=1}^d w_i x_i\), the term \(\sum_{i=1}^d x_i \gamma_i(1) + \sum_{i=1}^d (1-x_i) \gamma_i(0)\), which is a linear function of \(x\), and still leading to a tight convex relaxation. Here \(2d\) Gumbel variables are used instead of \(2^d\).
This seminal result led to a series of works using this result to approximate the log-partition function for parameter learning in intractable distributions where the maximization problem is efficient [5, 6].
Interestingly, the Gumbel trick is a simple consequence of a special property of a specific exponential family (here the exponential distribution). Some other exponential families (e.g., Gamma or Dirichlet) lead to different special properties with other nice consequences, but this is for future posts.
References
[1] Dima Kuzmin and Manfred K. Warmuth. Optimum follow the leader algorithm. Proceedings of the Conference on Learning Theory (COLT), 2005.
[2] George Papandreou, Allan L. Yuille. Perturb-and-MAP random fields: Using discrete optimization to learn and sample from energy models. Proceedings of the International Conference on Computer Vision (ICCV), 2011.
[3] John I. Yellott Jr. The relationship between Luce’s choice axiom, Thurstone’s theory of comparative judgment, and the double exponential distribution. Journal of Mathematical Psychology, 15.2: 109-144. 1977.
[4] Tamir Hazan and Tommi Jaakkola. On the Partition Function and Random Maximum A-Posteriori Perturbations. Proceedings of the International Conference on Machine Learning (ICML) , 2012.
[5] Andreea Gane, Tamir Hazan, and Tommi Jaakkola. Learning with maximum a-posteriori perturbation models. Proceedings of the Conference on Artificial Intelligence and Statistics (AISTATS), 2014.
[6] Tatiana Shpakova and Francis Bach. Parameter Learning for Log-supermodular Distributions. Advances in Neural Information Processing Systems (NIPS), 2016.
Nice post! May I suggest a small modification? In the last proposition, it would be better to write “… such that each value **(within and across the functions)** is sampled …” Otherwise, one would tend to equate the word “value” and the word “function”, which would make understanding harder, if not impossible.
Hi Wenjie
Thanks for the suggestions. What you suggest is indeed clearer. I will update the post.
Best
Francis
Hi Francis,
Some relevant reference (may be)
Lost Relatives of the Gumbel Trick
https://arxiv.org/pdf/1706.04161.pdf
-S
Cette fonction a une très longue histoire. Elle a été introduite par l’ingénieur du Corps des Mines, François Massieu en 1865 en thermodynamique et porte le nom de fonction caractéristique de Massieu. Voir l’article de Roger Balian sur le site de l’Académie des Sciences:
“François Massieu et les potentiels thermodynamiques”
https://www.academie-sciences.fr/en/Evolution-des-disciplines-et-histoire-des-decouvertes/francois-massieu-et-les-potentiels-thermodynamiques.html
C’est Massieu qui a inspiré Henri Poincaré (voir son cours de thermodynamique et de probabilité), son confrère du Corps des Mines, pour introduire la fonction caractéristique via la transformée de Laplace dans son cours de probabilité (il y a un log entre les deux). Elle est liée à la fonction génératrice des cumulants.
Cette fonction a été étudiée par les géomètres Jean-Louis Koszul et Ernest Vinberg sous le nom de fonction caractéristique de Koszul-Vinberg sur les cônes convexes homogènes saillants:
“Jean-Louis Koszul and the Elementary Structures of Information Geometry”
https://link.springer.com/chapter/10.1007/978-3-030-02520-5_12
Cette fonction caractéristique a été généralisée par Jean-Marie Souriau sur les orbites coadjointes des groupes de Lie via l’application moment, permettant de faire des statistiques sur des groupes de Lie. Koszul et Souriau ont été des normaliens élèves et disciples de l’oeuvre d’Elie Cartan:
“CARTAN-KOSZUL-SOURIAU Foundations of Geometric Structures of Information”
https://fgsi2019.sciencesconf.org/
Cette fonction avait été retrouvée par Maurice Fréchet dans son cours de l’IHP de 1939 et l’article de 1943 où il introduit la borne de Fréchet-Darmois, 6 ans avant Cramer-Rao, en étudiant les “densités distinguées”, densités pour lesquelles la borne est atteinte (densités exponentielles).
Mais la structure fondamentale de cette fonction caractéristique de Massieu réside dans le fait que sa transformée de Legendre donne l’Entropie; ce qui pour Souriau est la seule définition de l’Entropie. En fait ces potentiels de Massieu sont des fonctions invariantes de Casimir en théorie des représentations de Kirillov.
Cette fonction est parfois appelée fonction de Cramer et joue le rôle également de transformée de Fourier en algèbre (Min,+) et géométrie tropicale.
En géométrie de l’Information, cette fonction est très utile car son hessien nous donne la métrique de Fisher dans l’espace des paramètres des densités, invariante par reparamétrisation (Rao), invariante sous l’action des automorphismes des cônes convexes (Koszul), invariante sous l’action des groupes (Souriau).
La définition la plus générale de cette fonction est dans la structure qui en fait une fonction de Casimir en représentation adjointe, et l’Entropie la fonction de Casimir duale en représentation coadjointe:
https://www.preprints.org/manuscript/202003.0099/v1
Nous avons oublié de nos aînés, qui apprirent la géométrie projective jusqu’en 1948 au bac, que comme le rappellent Chasles, Darboux, Vesiot, Hadamard et Belgodère, la transformée de Legendre consiste “à substituer à la surface sa polaire réciproque par rapport à un paraboloïde”.
Great post, thanks!
You might find this link relevant, as it provides a Geometric view on the Gumbel-max trick https://statisfaction.wordpress.com/2020/06/23/categorical-distribution-structure-of-the-second-kind-and-gumbel-max-trick/
In the section, from exponential distribution to Gumbel distribution, I have difficulties deriving the expected value of that x-parametrized Gumbel distribution, could you explain more detail?
Given the link between the Gumbel distribution, we simply compute the expectation by an integral, which turns out to be exactly equal to the Euler constant defined in https://en.wikipedia.org/wiki/Euler%E2%80%93Mascheroni_constant#Integrals
Francis
In the section, from exponential distribution to Gumbel distribution, I don’t understand the derivation of the expected value of the Gumbel distribution. Could you elaborate?
Thank you
Thank you very much for the post. It is very helpful.
In the last proposition, if Gumbel distribution is a zero-mean distribution, why does it take $\x_i$ as its argument? How does this argument affect the Gumbel distribution?
Hi!
I use arguments as a way to access the component of a vector. That is, if $x_i$ takes 2 values 1 and 2, you should see $\gamma_i$ as a vector in two dimensions, with components $\gamma_i(1)$ and $\gamma_i(2)$.
Francis
Hello! Thanks for the very nice post.
In the dynamic programming example, you suggest that the Gumbel trick could be used to estimate the log-partition function of a tree graphical model by solving maximization of the Gumbel-perturbed problem; you conclude that this is not better than using the sum-product algorithm for trees.
Why is it that the second objection you make (on the linear programming example) does not hold? There are also 2^d possible configurations in the tree example.
Thanks again for all the posts!
Hi Romain!
In the tree example, there are indeed 2^d configurations, but a dedicated polynomial-time algorithm based on message passing to both maximize (like for LP) *and* compute a log-sum-exp function.
Francis
Hi Francis,
very interesting post indeed!
At the beginning of “Applications in machine learning” you write
“(a) the main goal is to approximate the expectation using a finite average or using stochastic gradients (then only the value of the maximum is used)”
How do you use stochastic gradients to approximate the expectation via the value of the maximum?
Thanks
Hi!
This was unclear. The expectation can be replaced by a sample average which is then minimized (Gumbel variables are sampled only once). But instead one can minimize the expectation by stochastic gradient where at each iteration, new Gumbel samples are used.
Francis